
What is Machine Learning?
Machine learning is the practice of using algorithms to analyze data, learn from that data and make a determination or prediction about new data.
What is Deep Learning?
Deep learning (DL) is a sub field of Machine Learning (ML) that uses algorithms inspired by the structure and function of the human brain's neural network called artificial neural network. As a sub field of ML, DL also uses algorithms to analyze data, learn from that data and make a determination or prediction about new data.
What is Supervised Learning and Unsupervised Learning?
That learning from data mentioned earlier can happen in two ways: Supervised and Unsupervised.
Supervised: Model learns and makes inferences from the data that has been already labeled.
Unsupervised: Model learns and makes inferences from unlabeled data.
ANN are computing systems that are inspired by the human brain's neural network. These network are a based on a collection of connected units called artificial neurons or neurons.
What is Gradient?
Visualize a bowl and suppose you want to get to the bottom of the bowl. One logical way to do this is to walk along the steepest direction and hope that you will reach the bottom. Gradient provides that steepest direction.
In Machine Learning, we are basically trying to reach an optimal solution (bottom of the bowl). The gradient is simply a vector which gives the direction of maximum rate of change. By taking steps in that direction, we hope to reach our optimal solution.
So for example, if you have the function its gradient would consist of n partial derivatives and would represent the vector field.
Gradient descent is an optimization algorithm used to minimize some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient. In machine learning, we use gradient descent to update the parameters of our model. Parameters refer to coefficients in Linear Regression and weights in neural networks.
A simpler way to understand what the bias is: it is somehow similar to the constant b of a linear function
It allows you to move the line up and down to fit the prediction with the data better. Without b the line always goes through the origin (0, 0) and you may get a poorer fit.
Also with the introduction of bias, the model will become more flexible.
Cost function tells us how well the neural network is performing. Our goal during training is to find parameters that minimize the cost function. For an example of a cost function, consider Mean Squared Error function:
The mean of square differences between our prediction
Whenever you train a model with your data, you are actually producing some new values (predicted) for a specific feature. However, that specific feature already has some values which are real values in the dataset. We know the closer the predicted values to their corresponding real values, the better the model.
Now, we are using a cost function to measure how close the predicted values are to their corresponding real values.
We also should consider that the weights of the trained model are responsible for accurately predicting the new values. Imagine that our model is y = 0.9*X + 0.1, the predicted value is nothing but (0.9*X+0.1) for different Xs. [0.9 and 0.1 in the equation are just random values to understand.]
So, by considering Y as real value corresponding to this x, the cost formula is coming to measure how close (0.9*X+0.1) is to Y.
We are responsible for finding the better weight (0.9 and 0.1) for our model to come up with a lowest cost (or closer predicted values to real ones).
Gradient descent is an optimization algorithm (we have some other optimization algorithms) and its responsibility is to find the minimum cost value in the process of trying the model with different weights or indeed, updating the weights.
We first run our model with some initial weights and gradient descent updates our weights and find the cost of our model with those weights in thousands of iterations to find the minimum cost.
One point is that gradient descent is not minimizing the weights, it is just updating them. This algorithm is looking for minimum cost.
In the field of machine learning and specifically the problem of statistical classification, a confusion matrix, also known as an error matrix.
A confusion matrix is a table that is often used to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known. It allows the visualization of the performance of an algorithm.
It allows easy identification of confusion between classes e.g. one class is commonly mislabeled as the other. Most performance measures are computed from the confusion. A good article on confusion matrix: https://www.geeksforgeeks.org/confusion-matrix-machine-learning/
Wikipedia has an interesting diagram to explain these concepts:

This concept can also be portrayed like below:

The derivative is the instantaneous rate of change of a function with respect to one of its variables. This is equivalent to finding the slope of the tangent line to the function at a point. Change in y-axis w.r.t. change in x-axis.It is also known as slope.

Its Range is between 0 and 1. It is a S — shaped curve. It is easy to understand and apply but it has major reasons which have made it fall out of popularity -
- Vanishing gradient problem
- Secondly , its output isn’t zero centered. It makes the gradient updates go too far in different directions. 0 < output < 1, and it makes optimization harder.
- Sigmoids saturate and kill gradients.
- Sigmoids have slow convergence.
Tanh - Hyperbolic Tangent function:
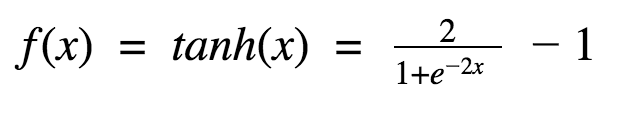
This looks very similar to sigmoid. In fact, it is a scaled sigmoid function. The range of the tanh function is from (-1 to 1). tanh is also sigmoidal (s - shaped).
Graphically:
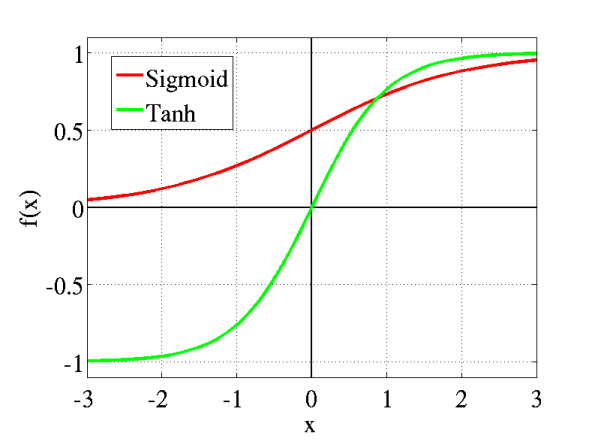
The advantage is that the negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero in the tanh graph.
ReLU - Rectified Linear Units:
The ReLU is the most used activation function in the world right now.Since, it is used in almost all the convolutional neural networks or deep learning.
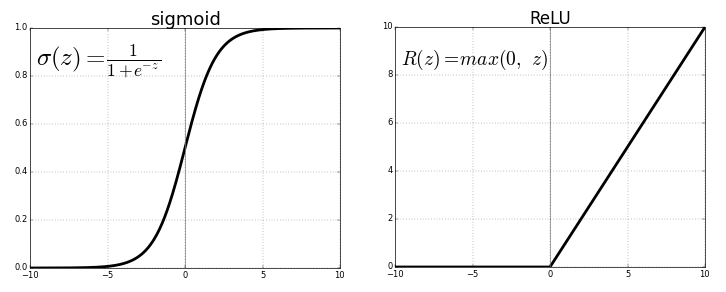
But the issue is that all the negative values become zero immediately which decreases the ability of the model to fit or train from the data properly. That means any negative input given to the ReLU activation function turns the value into zero immediately in the graph, which in turns affects the resulting graph by not mapping the negative values appropriately.
Now, which activation functions to use. Does that mean we just use ReLu for everything we do? Or sigmoid or tanh? Well, yes and no. When you know the function you are trying to approximate has certain characteristics, you can choose an activation function which will approximate the function faster leading to faster training process. For example, a sigmoid works well for a classifier ( see the graph of sigmoid, doesn’t it show the properties of an ideal classifier? ) because approximating a classifier function as combinations of sigmoid is easier than maybe ReLu, for example. Which will lead to faster training process and convergence. You can use your own custom functions too!. If you don’t know the nature of the function you are trying to learn, then maybe i would suggest start with ReLu, and then work backwards. ReLu works most of the time as a general approximator!
It is a measure of model’s performance. More technically, it is a weighted average of the precision and recall of the model, with results 1 being the best and 0 being the worst.
A matrix is a 2-dimensional array of numbers. If the array has x rows and y columns, we say that we have a matrix of size x×y.
A vector can be regarded as a special type of matrix. If a matrix has only one row or only one column it is called a vector. A row vector is a matrix of size 1×y, and a column vector is a matrix of size x×1.
Note: A matrix having only one row and one column is called a scalar.
Example The 1×1 matrix
A = [3]
is a scalar. In other words, a scalar is a single number.
Ref
See more examples here.
What is Jacobian Matrix?
It is a matrix which simply consists of first order partial derivative. In optimization algorithms the Gradient is represented by a Jacobian matrix.
Details explanation can be found here.
What are L1 and L2 regularization?
Regularization helps model to prevent overfitting. L1 and L2 are two most common type of regularization.
L1 and L2 are the most common types of regularization. These update the general cost function by adding another term known as the regularization term.
Cost function = Loss (say, binary cross entropy) + Regularization term
Due to the addition of this regularization term, the values of weight matrices decrease because it assumes that a neural network with smaller weight matrices leads to simpler models. Therefore, it will also reduce overfitting.
More detailed explanation can be found here.
You give us very useful information. Thanks
ReplyDeletehttps://magnimindacademy.com/